 Image Classifier
Image Classifier
- 8 mins Motivation
When I flew back to Taiwan in April 2020, I had to finish my mandatory 14-day quarantine after I landed. At that time, I was in my second year in UBC and just ended my 4 month coop at CarboNet. Only have been briefly introduced to machine learning, I knew the concept of it but never really had any experience with it at that time. I thought it would be useful to learn to code some machine learning models.
Language and Tools
- Python
- Keras
- TensorFlow
- AWS SageMaker (for training and deployment)
Implementation
For this image classifier, I am using the CIFAR-10 dataset. This is a dataset that consists of 10 classes of 6000 colour images. The classes are as listed below.
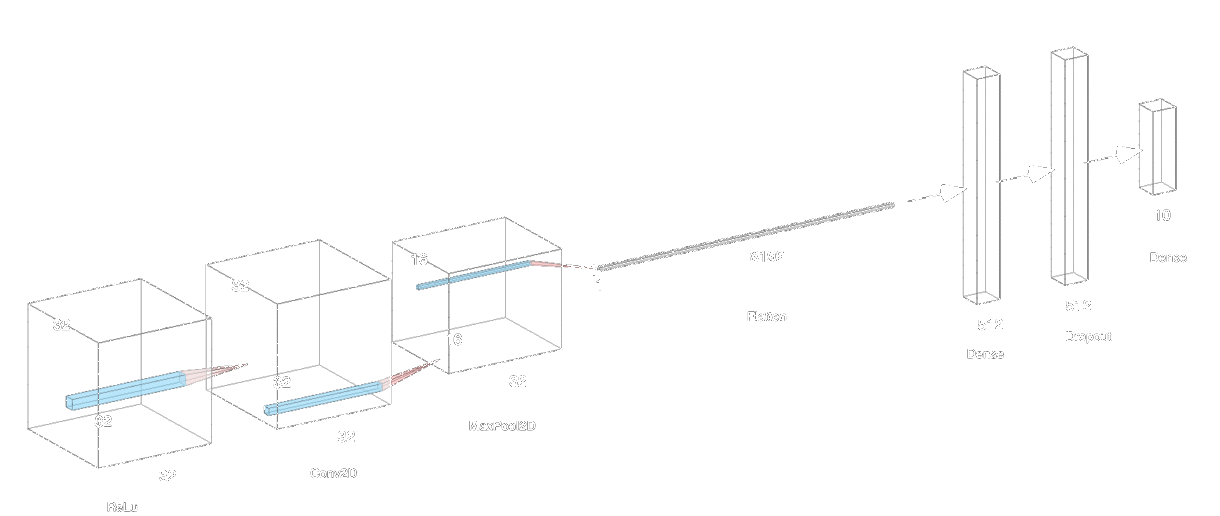
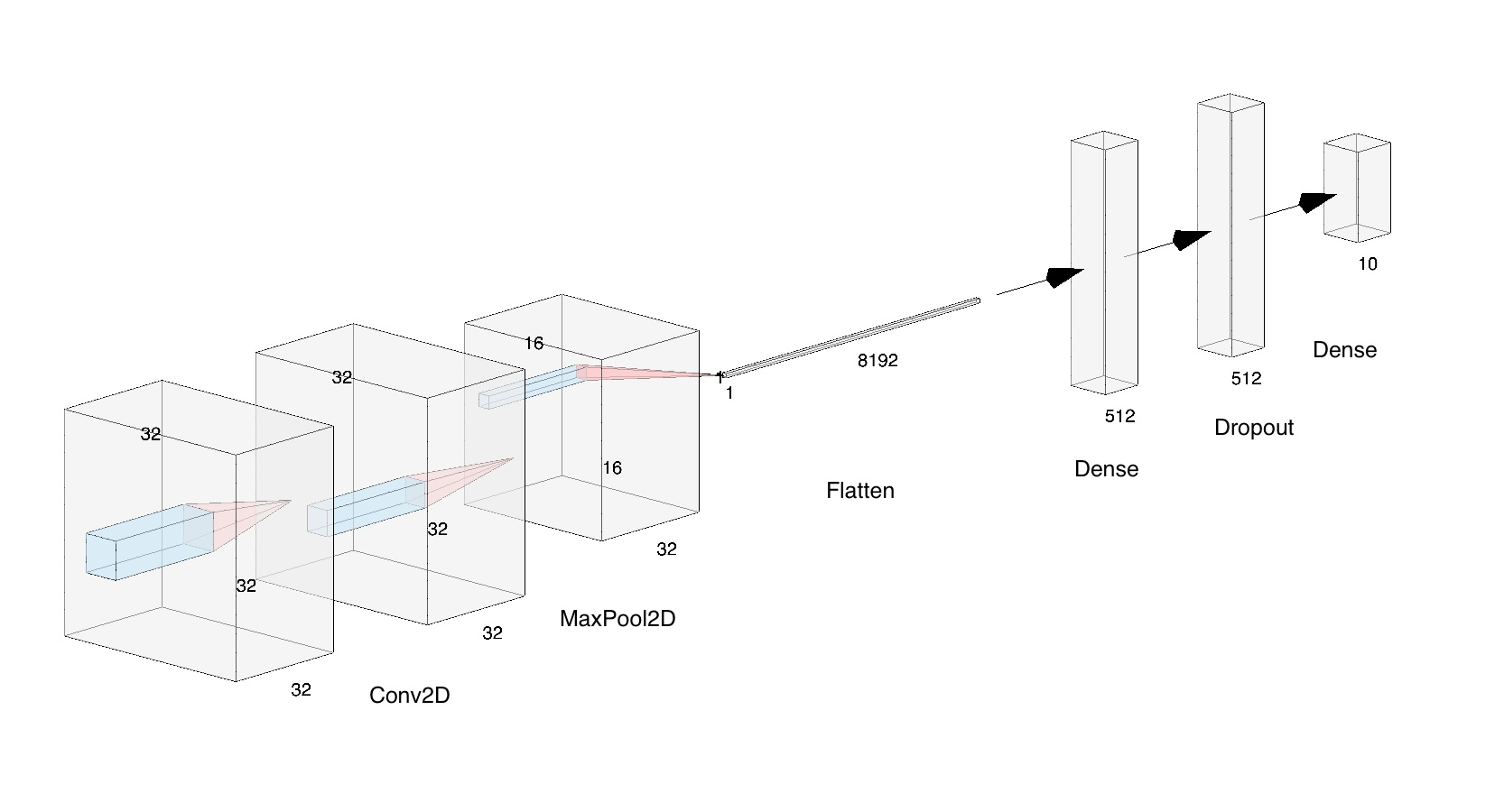
classes = ['airplane', 'automobile', 'bird', 'cat', 'dog', 'deer', 'frog', 'horse', 'ship', 'truck']After loading the training and testing dataset from keras.datasets.cifar10, we can start building our model using tensorflow.keras. After trying out some activation functions, I found that ReLu works the best (from what I read ReLu works for many other cases too). I applied ReLu in the Conv2D and the first dense layer, with a dropout layer that discards 30% of the neurons to improve the model’s reliability. Finally, we need to get a probability distribution of the final prediction out of 10 possible classes. Therefore, we apply the softmax activation function to achieve that. The model details are as shown below.
| Layer (type) | Output Shape | Param # |
|---|---|---|
| conv2d (Conv2D) | (None, 32, 32, 32) | 896 |
| max_pooling2d (MaxPooling2D) | (None, 16, 16, 32) | 0 |
| flatten (Flatten) | (None, 8192) | 0 |
| dense (Dense) | (None, 512) | 4194816 |
| dropout (Dropout) | (None, 512) | 0 |
| dense_1 (Dense) | (None, 10) | 5130 |
| Model Specs | # |
|---|---|
| Total params | 4,200,842 |
| Trainable params | 4,200,842 |
| Non-trainable params | 0 |
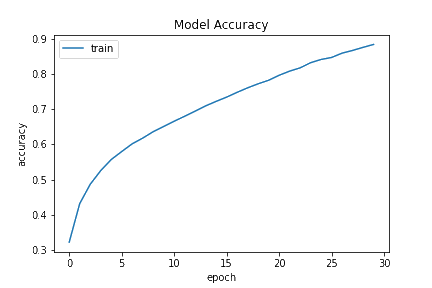
Training
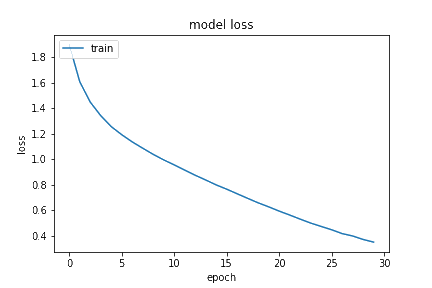
We train the model for 30 epochs and with 32 batch size. The accuracy of the model was 88.48%.
Validation
To validate the trained model on a unseen dataset, I wrote a simple script to calculate the number of images that the model correctly predicted.
num_correct = 0
for i, img in enumerate(test_images):
test_image_data = np.asarray([img])
prediction = model.predict(x=test_image_data)
max_prediction = np.argmax(prediction[0])
if test_labels[i][max_prediction] == 1:
num_correct += 1
else:
plt.imshow(test_images[i], interpolation='nearest')
plt.show()
print(labels_array[max_prediction])The model was able to successfully predict 69.39% of 10000 test images. Most of the mispredictions were between 'airplane'/'bird' or 'horse'/'dog'. Might need to tweak the model parameters a bit more in the future to get a better result!